SHOW NOTES
Podcast Recorded on January 19th, 2024 (AEST)

HOSTS
AB – Andrew Ballard
Spatial AI Specialist at Leidos.
Robotics & AI defence research.
Creator of SPAITIAL

Helena Merschdorf
Marketing/branding at Tales Consulting.
Undertaking her PhD in Geoinformatics & GIScience.

Mirek Burkon
CEO at Phantom Cybernetics.
Creator of Augmented Robotality AR-OS.

Violet Whitney
Adj. Prof. at U.Mich
Spatial AI insights on Medium.
Co-founder of Spatial Pixel.

William Martin
Director of AI at Consensys
Adj. Prof. at Columbia.
Co-founder of Spatial Pixel.
FAST FIVE – Spatial AI News of the Week
From William:
The Rabbit R1 – part assistant, part completely-new-interface-paradigm?
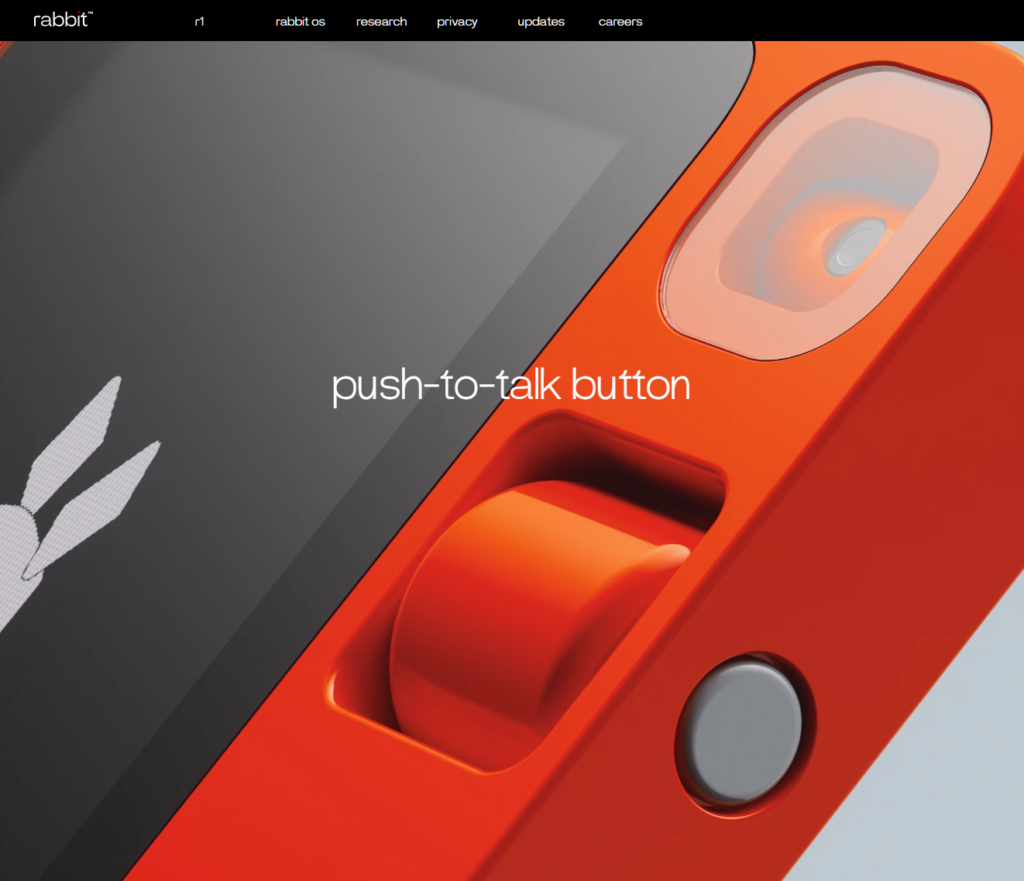
From the Rabbit Research Team:
“We have developed a system that can infer and model human actions on computer applications, perform the actions reliably and quickly, and is well-suited for deployment in various AI assistants and operating systems. Our system is called the Large Action Model (LAM). Enabled by recent advances in neuro-symbolic programming, the LAM allows for the direct modeling of the structure of various applications and user actions performed on them without a transitory representation, such as text. The LAM system achieves results competitive with state-of-the-art approaches in terms of accuracy, interpretability, and speed. Engineering the LAM architecture involves overcoming both research challenges and engineering complexities, from real-time communication to virtual network computing technologies. We hope that our efforts could help shape the next generation of natural-language-driven consumer experiences.”
From Helena:
Opus Clip for accurate video excerpts, transcriptions and on-the-fly subtitling


From Mirek:
The global project to make a general robotic brain


The generative AI revolution embodied in tools like ChatGPT, Midjourney, and many others is at its core based on a simple formula: Take a very large neural network, train it on a huge dataset scraped from the Web, and then use it to fulfill a broad range of user requests. Large language models (LLMs) can answer questions, write code, and spout poetry, while image-generating systems can create convincing cave paintings or contemporary art.
https://spectrum.ieee.org/global-robotic-brain
From AB:
AI-powered super-resolution: going from ‘enhance, enhance’ to ‘ok, wow’.

My Fast Five for this week is https://mingukkang.github.io/GigaGAN/ – but not the fact that this is a GAN, making any generative artwork you can prompt it with – no – I’m more interesting the insane super-resolution that its doing to the initial output: going from 128×128 pixel GAN output, all the way up to a 4000×4000 pixel image. About 1000 times the input.
So while it’s very obviously ‘making stuff up’, the question for us all is: is it making stuff up, semantically ie: with a level of understanding of objects/depth/relationships – or is it just superbly trained to go from small–>huge images, until the meat sacks in the loop (us!), think that its simply magic…?
https://mingukkang.github.io/GigaGAN/
To absent friends.