A quick prehistory on GANs
GANs (Generative Adversarial Networks) are the backbone of recent computer generated imagery tools, working on the basis that human supervision of AI/ML models can produce some of the best results, but active monitoring is time consuming – how about we tie the output of our AI model to the input of a second model as the supervisor – and just let the two models form a runaway reaction loop, and come back when they’re finished and see what they made…? In this way, the learner and the supervisor halves of the GAN form a symbiotic training pair, operating at many orders of magnitude faster that any human intervention.
Such was the success of the first major GAN: StyleGan 2, so brilliantly displayed to the world at http://thispersondoesnotexist.com:

Thispersondoesnotexist makes a completely novel human face on each page reload, to what was then (the middle of 2020) a previously unheard of image resolution – to the point where hackers then switched to using this service to create fake social media profiles, versus simply stealing profile pics, which could be easily reverse-searched. Notable ‘tells’ for thispersondoesnotexist were: 1) eyes always being in the exact same spot, and completely horizontal; 2) mismatching earrings (see above), and 3) dubious background fills. Apart from that, the results were quite breathtaking. Generative AI was off and running – for 2D faces, at least.
The GAN explosion
One major caveat of GANs is that the supervising model set the conditions for the output of the main model – effectively setting in stone what the focus of the primary model is trained to do. Another caveat is that the supervising model requires a lot of prior training in detecting/scoring the subject matter at hand. Both of these caveats, combined, mean that GANs were single-modal and single-topic – ie: RGB imagery, of a single concept.
This led to the rise of http://thisxdoesnotexist.com – a collection of ‘x’-specific GANs, mostly using the StyleGan 2 engine:
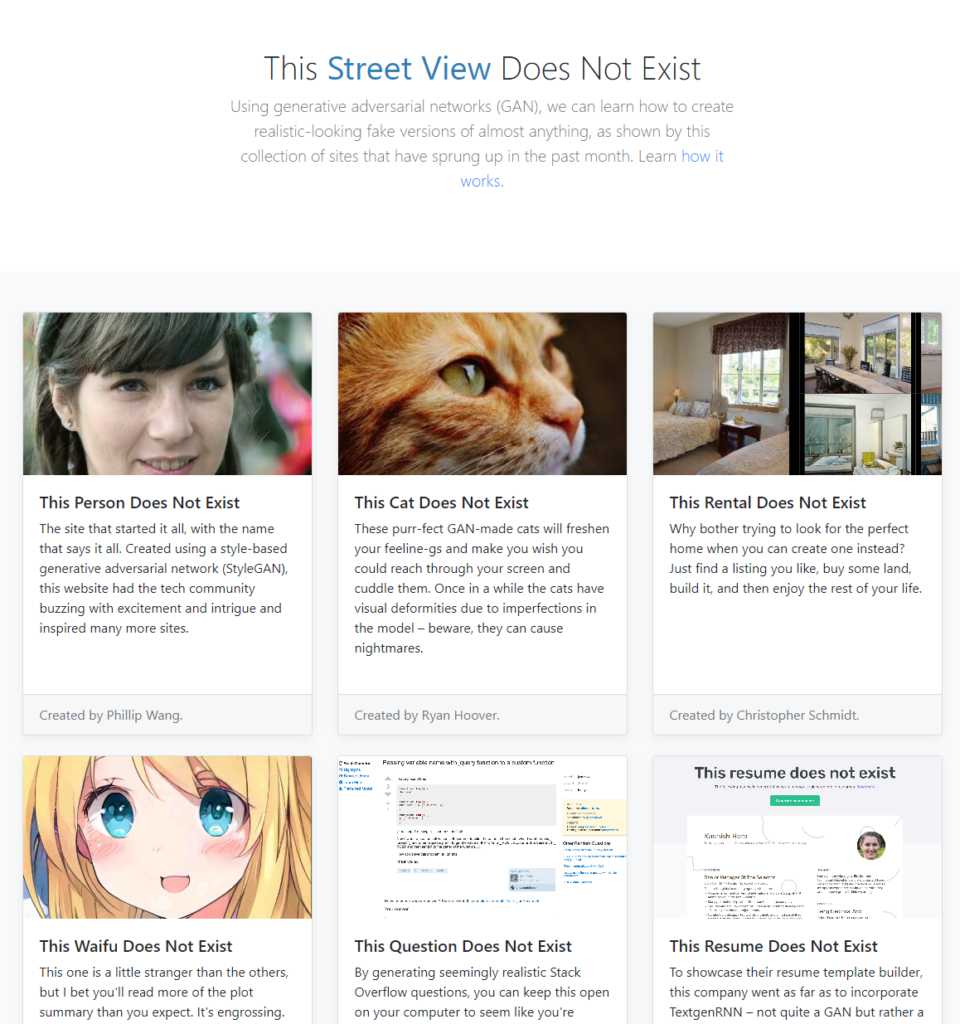
*The author’s attempt to join this party was This PRODUCT does not exist – an idea that if you wanted to buy a shirt in the style of design A, but material B – could the model synthesize one for you? Thankfully, other models are taking on this challenge with gusto, with many variants of text-to-complete-human-fashion-imagery models. We’ll return to this topic in a future article.
Spatially-aware GANs
While usable 2D imagery on topic-specific subject was solved with StyleGan 2 et al, the transition to 3D was noticeably absent. Early models that could output 3D information had to revert back to low-polygon meshes, which were only useful in very limited use cases – recreating chess pieces was an early standard.
This week, NVIDIA Research Labs unveiled WYSIWYG – What you See Is What You GAN – a model led by Alex Trevithick – an *intern* at the time. (Author’s note: NVIDIA hires *the best* interns!)
The main focus on WYSIWYG is the ability to simultaneously generate super-resolution 2D RGB images AND massive polygon count/near-perfectly normalised 3D meshes.
The subject matter is limited to human faces – and cat faces, at present. But similarly to the ‘thisx’ explosion, no doubt new domains will follow in the coming weeks.
The following are a series of examples from the WYSIWYG Project Page:

Even more impressive are the videos showing the levels of detail possible with their models, including what appears to be the semantic understanding of overlapping objects in 3D-space, such as where glasses meet the nose, and cat whiskers and beard stubble both have unprecedented levels of precision.
When comparing GANs to LLM-based image generators, remember that GANs are over-trained to near-perfection on topic-specific concepts, whereas image diffusion from a prompt input is aiming at a generalist approach, in any variety of styles. Both techniques are aiming at recreating reality, yet approach this goal from nearly polar opposite methodologies.
NVIDIA’s Paper and more examples are on their Project Page. Code not available in the public domain, yet I imagine will be reproduced open-source within the next few weeks.